
Fine-Tuning GPT to Mimic Myself
After taking the course Natural Language Processing this semester at UC Berkeley, I was left eager to continue to explore NLP and LLMs. We covered a lot of ground, but what really stood out to me was learning how to fine-tune Large Language Models (LLMs). This inspired me to take on a unique personal project: tweaking a language model to sound just like me. The ultimate test would be to see if my friends and family could differentiate between chatting with the AI and the real me.
Building a language model from the ground up is prohibitively expensive, often requiring an investment of hundreds of thousands of dollars for basic language learning. Therefore, my approach involved fine-tuning an existing model. I chose the GPT-3.5-turbo model, the same technology behind ChatGPT. However, achieving a high level of personalization and knowledge would still require a substantial amount of data.
Fortunately, GDPR mandates that companies provide individuals with their personal data upon request. This regulation enabled me to collect a significant volume of data for my project. I downloaded 201,000 messages from Facebook Messenger, to use for fine-tuning the model.
Data
Training of the language model requires high-quality data that primarily reflects my writing style. The objective was to teach the model to emulate my unique style, rather than the styles of others who have communicated with me. To achieve this, I made a strategic decision to exclude messages from group chats, as they often are a blend of various styles from different participants, which could dilute the distinctiveness of my writing style. Consequently, all 254 group chat threads were removed from the dataset.
Recognizing that my earlier writing might not accurately represent my current style, I decided to eliminate older messages. Specifically, I discarded 19,000 text messages dated before 2019.
Following these exclusions, I was left with a dataset of 78,000 text messages. These messages, being recent and solely from one-on-one chats, provided a focused and quality dataset.
The final step was to format the data in the way GPT-3.5 require:
{
"messages": [
{
"role": "system",
"content": "Marv is a factual chatbot that is also sarcastic."
},
{
"role": "user",
"content": "What's the capital of France?"
},
{
"role": "assistant",
"content": "Paris, as if everyone doesn't know that already."
}
]
}
The example over illustrates the data format required for a single conversation. As the model is expected to keep everything in mind from previous messages in a single conversation, I will split Messenger chats into smaller conversations. I consider a conversation to be done and start a new one if there is more than 8 hours since the first message in that conversation was sent. After splitting the chats into smaller conversations, I ended up with 4 400 smaller conversations total with an average of 11 messages per conversation.
In the data format example, the role field is used to tell the model who the message is sent from. In my case, the messages I have received will be given the role user, while messages I have sent will be given the role assistant. The system role is used to give the model a behavior description that is extra emphasized throughout the conversation. In the system message, I included a short sentence describing myself and included the name of the person the chat is with, so that the model can learn to chat differently with different people.
OpenAI Data Format Validation and Cost Estimation
Fine-tuning a sophisticated language model like GPT-3.5 requires extensive computational resources, well beyond the capabilities of a standard computer. For my project, training the model on my dataset, which comprised of 1 188 834 tokens, 4 epochs costs $38 and completed in approximately 30 minutes.
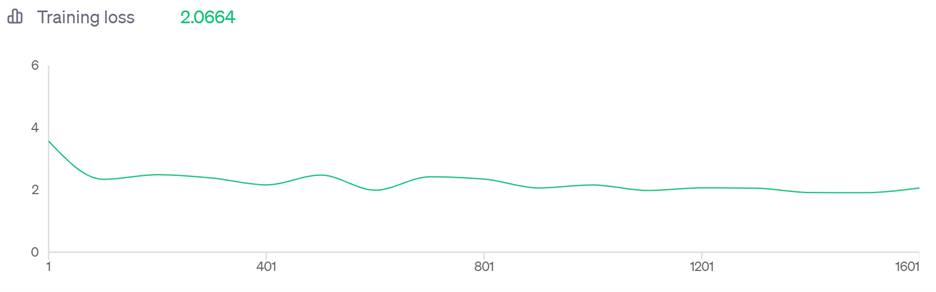
The initial rapid decline in training loss suggests that the model quickly adapted to the general format and style of informal messaging. This phase reflects the model's ability to grasp the key characteristics of conversational text, such as tone, structure, and common phrases.
However, the long continuation of plateauing improvement indicates a more nuanced challenge. It suggests that while the model learned to generate responses in an informal style, it found it more challenging to precisely predict and replicate the specific content of my messages. This could be due to the varied nature of personal communication where the context of the responses plays a significant role.
Evaluation using the Turing Test
After training the model, I conducted a practical test with friends and family to determine if they could differentiate between the AI and myself, evaluating the model's effectiveness in mimicking my communication style.


The performance of the fine-tuned model reveals some interesting aspects. Initially, the model engages well in conversations, even accurately referencing topics like the 'Operating Systems' course that I have taken, indicating its ability to grasp and utilize relevant personal information. However, the model also exhibits a tendency towards generating irrelevant or nonsensical content, often referred to as "hallucinations." An example is the message: “I would have asked neverland if he knows how to do this”. It's important to note that the majority of the training data for the model consisted of Norwegian text messages, with only a minority in English. Despite this, the issue of the model producing irrelevant or nonsensical content was observed consistently across both languages.
During practical evaluations with friends and family, the model initially managed to generate appropriate responses. However, like the example above, it tended deviate into generating random and unrelated content after a few exchanged.
Although I could continue the training, the training loss chart indicates that further training might lead to only marginal improvements. An alternative approach could be to fine-tune a smaller language model, where my data would have a more significant impact compared to the extensive training that larger models undergo. However, a notable limitation is the absence of a smaller model fluent in Norwegian, which is the primary language of my dataset. Despite challenges, the model was able to somewhat adapt to my writing style, and I recognized that it captures variations in my communication with different individuals. Yet, fully replicating my text messaging style proves challenging, largely due to the context-dependent nature of personal communication and the influence of real-life events on the conversation. The hope is that ongoing research and innovation in AI will address these challenges, leading to more nuanced and contextually aware language models and fine-tuning techniques.
All source code availble on GitHub repo
Written by Sondre Sørbye 10.12.2023
For questions, email sondre@magson.no